I have written a guide on testing storage with VM-fleet that goes well with this.
Generally speaking when testing something new I will build it and tear it down a few times before I'm happy. Then when I'm sure I know what I'm doing I will do a final build from a build checklist that I have made, or a script if it's appropriate. That way I can be sure that I have done everything I need to do, the hosts are consistent and I have a record for future reference.
This is round 2 of my cycle so there may still be some errors. I will correct later if I find anything in round 3.
hardware
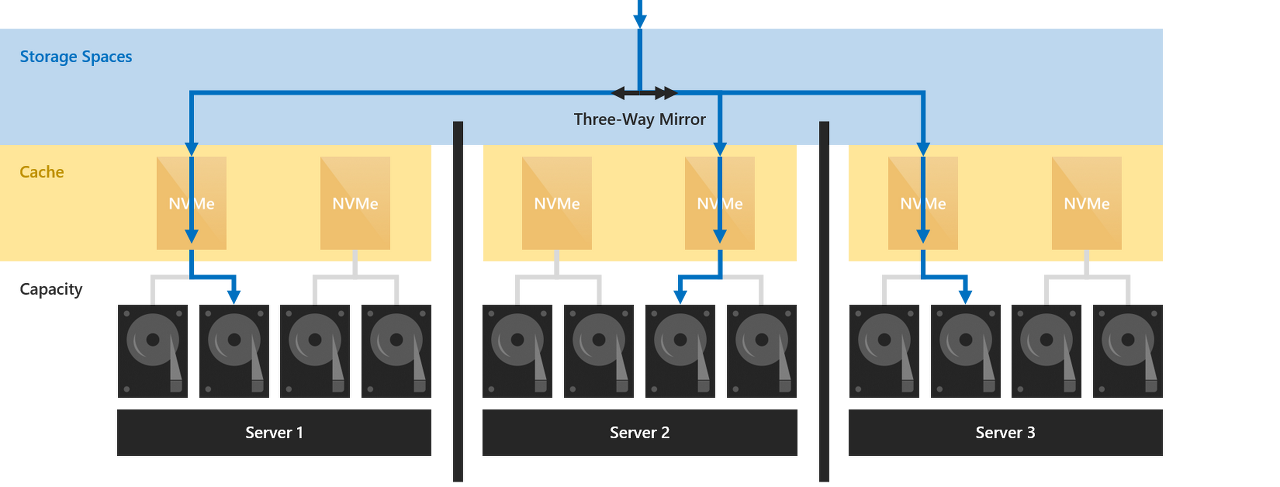
Storage spaces direct (S2D) wants all the hosts to be similar, in that they have the same type and amount of disks, and I would also recommend the same CPU. The storage CPU load for each volume takes place on the host that owns that volume. I think having mismatched CPU's would probably affect the performance of that volume significantly. You also need multiple RDMA capable 10GB interfaces.
I have 3 hosts that look like this:-
HP DL380 Gen9
Dual E5-2640v5
256GB RAM
2 x Chelsio 10GB network cards
1 x HP P440 Raid controller.
2 x HP H240 HBA
16 x 480GB Intel enterprise SSD's
2 x SATA drives
Switching, I have a pair of Arista switches for the 10GB and some Aruba affair for the 1GB.
I should also point out that this is currently POC kit bought specifically for this and that once I am happy with it all we will likely use this same kit in our public cloud environment.
The physical architecture is your standard cluster with redundant networks. I'm not going to document that but here.
Installation
First thing is to install Windows Server 2016 and all its updates. It also a good idea to properly name all your NIC interfaces as that will make it a lot easier to identify them later on.
Next, we need to install all the windows features required for S2D. This script should get them all in one go
Install-WindowsFeature -Name "Data-Center-Bridging","Failover-Clustering","Hyper-V","RSAT-Clustering-PowerShell","RSAT-Clustering-Mgmt","Hyper-V-PowerShell" -Restart
This will likely need a reboot.
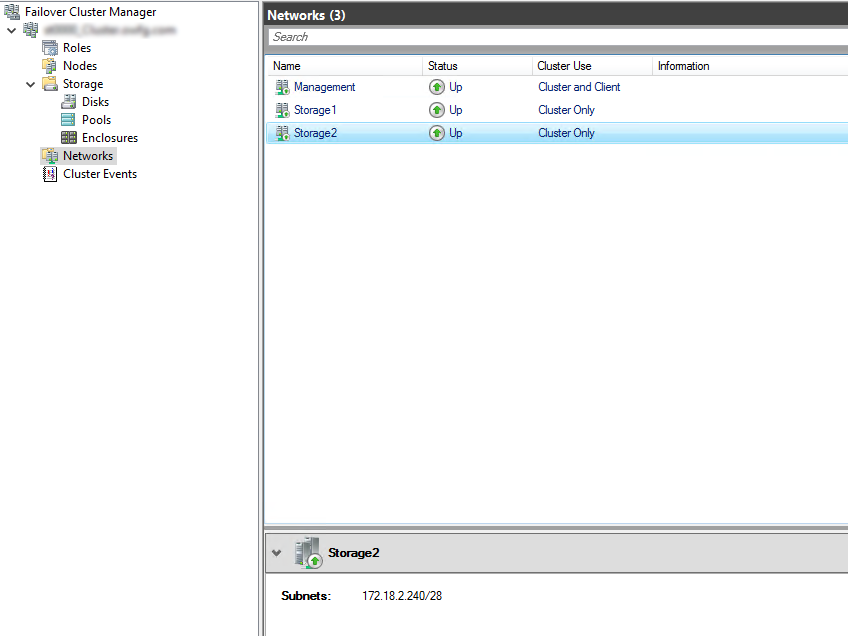
Once all this is done we can start putting together the required networking. This requires a little thought.
Network
S2D uses switch embedded teaming (SET). This is not the same as the switch teaming you may have used before. It has no GUI and can only be done from PowerShell. You need to be using SET in order to use the RDMA feature of your network cards. Switch embedded teaming also has support for some other features not available in standard NIC teaming. Microsoft has written a lovely little guide for you here. I warn you it's pretty long...
Depending on your choice of NIC you may also need to do some additional switch config to get RDMA to work. I chose a Chelsio card that has an RDMA implantation called iWarp, that doesn't need any specific switch config. It seemed like the easiest thing to do.
Now we start. The first thing we need to do is to create a QoS policy and give SMB high priority and a guaranteed allocation. You don't need to do this but it makes sense, especially in a hyper-converged environment where there may be resource contention.
You need to execute the following commands on all the servers that you plan to be in your cluster.
New-NetQosPolicy "SMB" -NetDirectPortMatchCondition 445 -PriorityValue8021Action 3
Enable-NetQosFlowControl -Priority 3
Disable-NetQosFlowControl -Priority 0,1,2,4,5,6,7
New-NetQosTrafficClass "SMB" –Priority 3 –BandwidthPercentage 30 –Algorithm ETS
The last line of that code essentially reserves 30% of the network specifically for S2D, which is what we want.
Now we need to enable the QoS policy on the relevant interfaces. To get a list of the NIC's run the following
Get-NetAdapter | FT Name, InterfaceDescription, Status, LinkSpeed
Which will give you something like this
Name InterfaceDescription Status LinkSpeed
---- -------------------- ------ -------
StorageNIC1 Chelsio Network Adapter #4 Up 10 Gbps
Ethernet 3 Chelsio Network Adapter #3 Disconnected 0 bps
VLAN 10 Microsoft Network Adapter Multiplexor Driver Up 2 Gbps
StorageNIC2 Chelsio Network Adapter #2 Up 10 Gbps
Ethernet Chelsio Network Adapter Disconnected 0 bps
Embedded LOM 1 Port 4 HP Ethernet 1Gb 4-port 331i Adapter #4 Disconnected 0 bps
Embedded LOM 1 Port 3 HP Ethernet 1Gb 4-port 331i Adapter #3 Disconnected 0 bps
Embedded LOM 1 Port 2 HP Ethernet 1Gb 4-port 331i Adapter #2 Up 1 Gbps
Embedded LOM 1 Port 1 HP Ethernet 1Gb 4-port 331i Adapter Up 1 Gbps
I need the policy on my 10GB storage interfaces, which I helpfully labeled during the hardware install. The other 2 are for migration and client traffic so won't be used for storage traffic and therefor don't need the policy.
Enable-NetAdapterQos –Name "StorageNIC1","StorageNIC2"
That bit is not done. We need to create the virtual switch and sort out the teaming (SET)
Again we will need the name of the storage NICs, which you should have from the previous step.
So we create the vSwitch
New-VMSwitch –Name vStorage –NetAdapterName "StorageNIC1", "StorageNIC2" –EnableEmbeddedTeaming $true
And now for the bit that I struggled to grasp for a while. Creating the vSwitch creates a single interface that has the name of the switch. This seems like it would be the vNIC you should be using. However, in testing, I have discovered that if I assign an IP to this vNIC and simulate failure in the physical NICS it does fail-over, but it takes a long time. Too long. So what we do is create 2 additional vNICs connected to the vSwitch, and map them to the physical. Essentially creating 2 diverse paths and allowing us to use the full 20GB of the network.
If one of the NIC's fails they IP will still fail-over to the other, and it still takes a long time, however, it doesn't matter due to the second path.
Add-VMNetworkAdapter –SwitchName vStorage –Name SMB_1 –managementOS
Add-VMNetworkAdapter –SwitchName vStorage –Name SMB_2 –managementOS
Set-VMNetworkAdapterVlan -VMNetworkAdapterName "SMB_1" -VlanId 48 -Access -ManagementOS
Set-VMNetworkAdapterVlan -VMNetworkAdapterName "SMB_2" -VlanId 48 -Access -ManagementOS
Once this is done restart the vNICs
Restart-NetAdapter "vEthernet (SMB_1)"
Restart-NetAdapter "vEthernet (SMB_2)"
And then we enable RDMA on these vNICS
Enable-NetAdapterRDMA "vEthernet (SMB_1)", "vEthernet (SMB_2)"
Finally, we assign them to a physical interface.
Set-VMNetworkAdapterTeamMapping -VMNetworkAdapterName "SMB_1" –ManagementOS –PhysicalNetAdapterName "StorageNIC1"
Set-VMNetworkAdapterTeamMapping -VMNetworkAdapterName "SMB_2" –ManagementOS –PhysicalNetAdapterName StorageNIC2"
Now we check if the relevant interfaces are set up correctly.
Get-SmbClientNetworkInterface
You should see this
Interface Index RSS Capable RDMA Capable Speed IpAddresses Friendly Name
--------------- ----------- ------------ ----- ----------- -----------
49 True True 20 Gbps {fe80::1964:a4a2:5f4d:b7e8,10.2.120.21} vEthernet (SMB_1)
53 True True 20 Gbps {fe80::ac59:19fa:1685:1247,10.2.121.21} vEthernet (SMB_2)
RDMA is enabled.
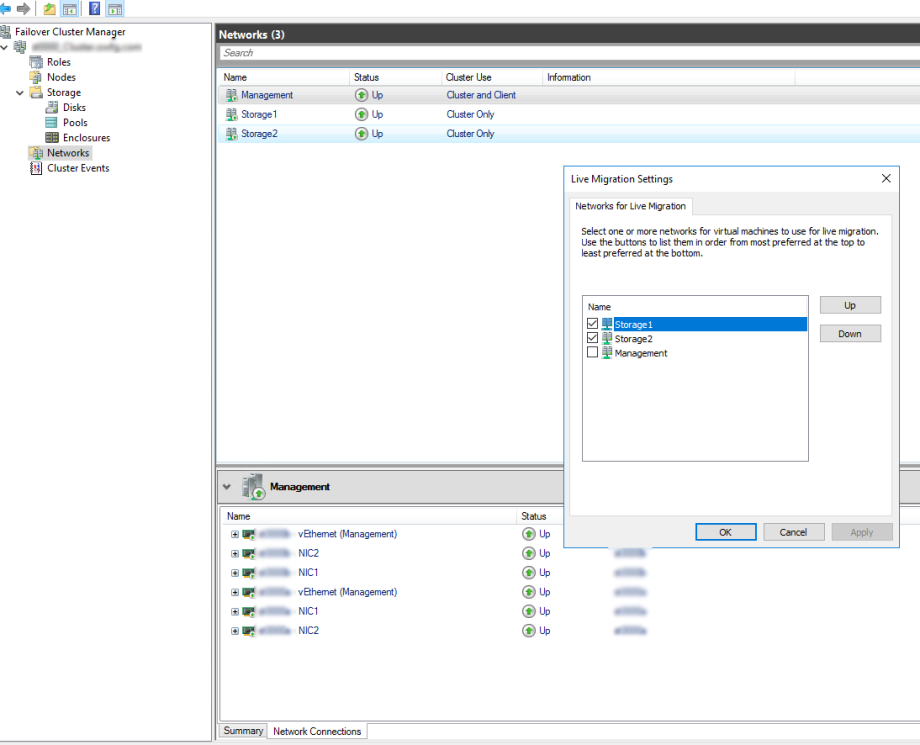
At this point, it's a good idea to assign your IP address and do some testing. Make sure things fail-over as expected, at the very least to make yourself familiar with what to expect from this sort of configuration.
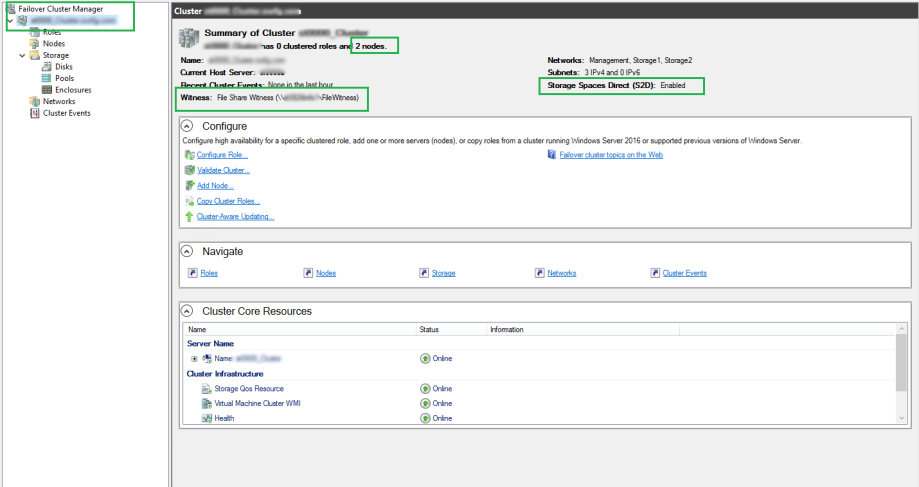
That's the networking done, now we move onto creating the cluster.
Cluster
The first thing to do is some cluster tests to make sure we haven't forgotten anything.
Test-Cluster –Node MachineName1, MachineName2, MachineName3, –Include "Storage Spaces Direct", "Inventory", "Network", "System Configuration"
For me this threw up an error. The vNIC that is created when we created the switch I mentioned earlier has no IP config assigned. You can ignore this or better still disable that interface. Once I did this the cluster validation came back as OK. So now we can move on and create the cluster.
New-Cluster -Name clustername -StaticAddress x.x.x.x –Node MachineName1, MachineName2, MachineName3, –NoStorage
You need the -NoStrage argument as otherwise it will capture all the disks and add them to the cluster. You don't want this yet.
Now depending how many nodes you have you may want to create a witness for the cluster, in the form of another server of a quorum. I assume you know how to so that and will if needed.
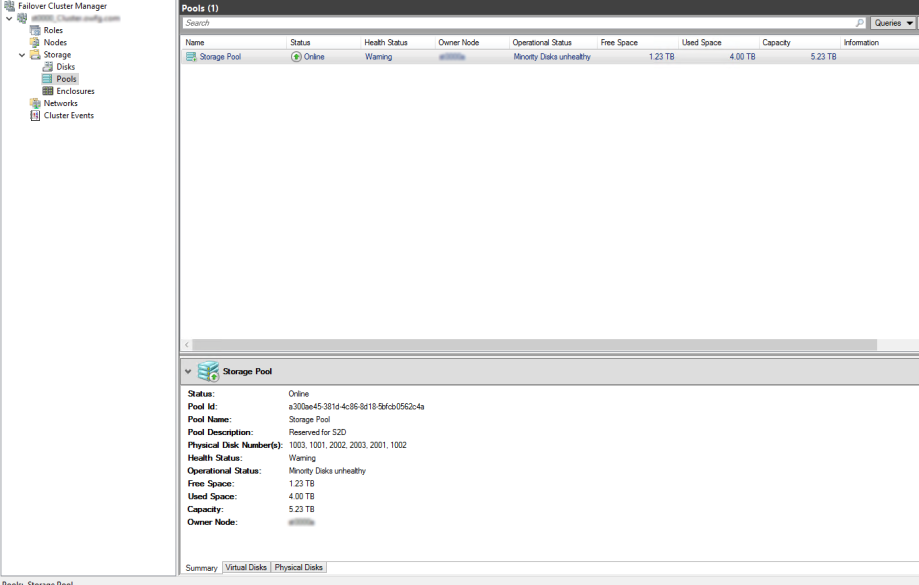
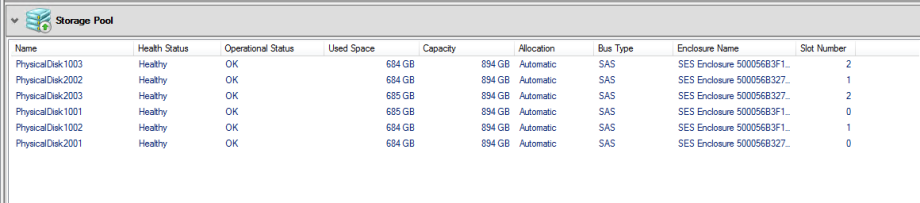
S2D
Now we get to the part where we enable storage spaces direct and add the S2D compatible disks to the storage pool. According to Microsoft S2D wants "Clean" disks. No existing partition data on them and give you this script to clean your disks.
icm (Get-Cluster -Name <cluster or node name> | Get-ClusterNode) {
Update-StorageProviderCache
Get-StoragePool | ? IsPrimordial -eq $false | Set-StoragePool -IsReadOnly:$false -
ErrorAction SilentlyContinue
Get-StoragePool | ? IsPrimordial -eq $false | Get-VirtualDisk | Remove-VirtualDisk -
Confirm:$false -ErrorAction SilentlyContinue
Get-StoragePool | ? IsPrimordial -eq $false | Remove-StoragePool -Confirm:$false -
ErrorAction SilentlyContinue
Get-PhysicalDisk | Reset-PhysicalDisk -ErrorAction SilentlyContinue
Get-Disk | ? Number -ne $null | ? IsBoot -ne $true | ? IsSystem -ne $true | ?
PartitionStyle -ne RAW | % {
$_ | Set-Disk -isoffline:$false
$_ | Set-Disk -isreadonly:$false
$_ | Clear-Disk -RemoveData -RemoveOEM -Confirm:$false
$_ | Set-Disk -isreadonly:$true
$_ | Set-Disk -isoffline:$true
}
Get-Disk |? Number -ne $null |? IsBoot -ne $true |? IsSystem -ne $true |? PartitionStyle -eq RAW | Group -NoElement -Property FriendlyName
} | Sort -Property PsComputerName,Count
Out of curiosity I tried to enable S2D with out doing this and unsurprisingly it failed. Don't skip this step, but also be aware this will flatten all the disks in the host. If you want to be more precise you may want to try using DiskPart.
Finally we enable storage spaces direct.
Enable-ClusterStorageSpacesDirect –CimSession <ClusterName>
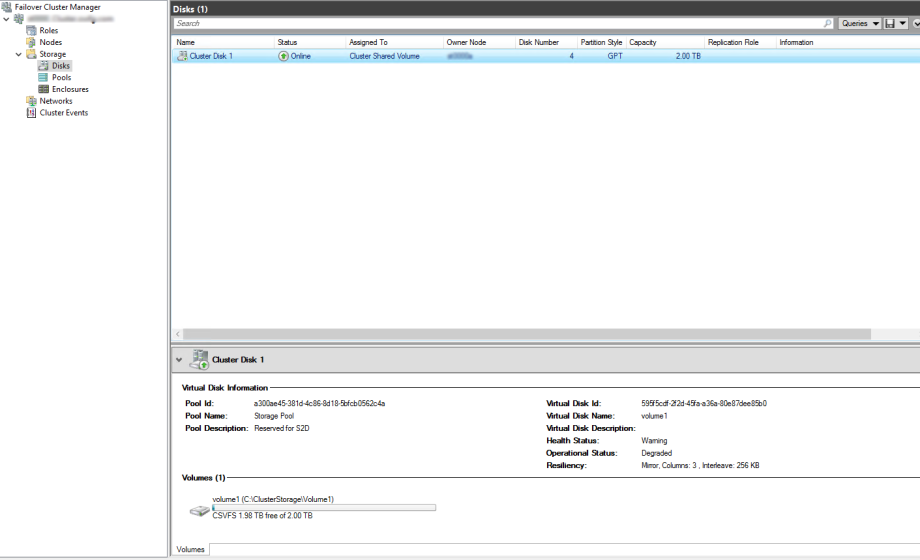
And we are done. You can now create vdisks and Volumes from the GUI if you wish but I would recommend that you use New-Volume in PowerShell as there are some specifics you may want to add to you new disks.
I will write another guide on that next I think.
If you have any feedback on this please comment bellow.

















{kind=link}