
This blog post should have been posted quite some time ago, however, after numerous revisions and the details in the post, you’ll understand why.
In this post I will demonstrate creating a converged network fabric in SCVMM 2012R2. This converged network will consist of logical network adapters, QoS, NIC (vNIC) teaming, and network adapters.
Step 1, Understand your infrastructure
To begin, my environment is using a Cisco UCS (B200 M4) back end, with Cisco Nexus 9K switches and of course Hyper-V (Windows 2012R2) as its hypervisor. The UCS profile used here, has been provisioned with 7 vNICs and dedicated VLANs for each vNIC to isolate the traffic between the networks. The 7 vNICs for the following jobs (see below). All vNICS have a 10GB interface.
- iSCSI-A (traffic to the SAN controller 1)
- iSCSI-B (traffic to the SAN controller 2)
- CSV-Heartbeat
- Live Migration
- Management
- Server-A (VM Production traffic)
- Server-B (VM Production traffic)
Server-A and Server-B vNICs we will team, but we will get into that later.
Step 2, we need understand what all these vNICs are intended for. The logical networks below illustrate the purpose of each network.
- SAN/Storage (1) (iSCSI-A) – This network will be for access storage via iSCSI on SAN controller 1. In this environment, we will have two VLANs for redundancy, thus two iSCSI networks.
- SAN/Storage (2) (iSCSI-B) – see above. This network will be for access storage via iSCSI on SAN controller 2.
- Live Migration – This network will be communication between the hypervisors to transfer VM memory, states, etc.
- CSV/Heartbeat – This network will be used by the cluster to communicate a healthy (online) state of the environment.
- Management – This network will be used to manage the Hyper-V/hypervisors. SCVMM will make use of this network to communicate to the Hyper-V nodes.
- VM Traffic (Server-A + Server-B) – This network will be intended communication for VMs and VMs only. This will be not only a redundant network, but a teamed network to allow additional I/O throughout. As mentioned, all vNICs are on a 10GB interface, teaming these two vNICs/networks will allow I/O to operate at 20GB/s.
Please refer to Microsoft article further details, HERE.
Step 3, SCVMM – Create Logical Network(s)
Within SCVMM, you will now need to create your logical networks within the Fabric pane. As mentioned, I am using VLANs to isolate my traffic. I am also planning to have 15 VM network environments with each having its own dedicated VLAN, VLAN 101 through 116, ie. 10.47.101-116.x. Likewise, dedicated VLANs for iSCSI, Live Migration, etc.
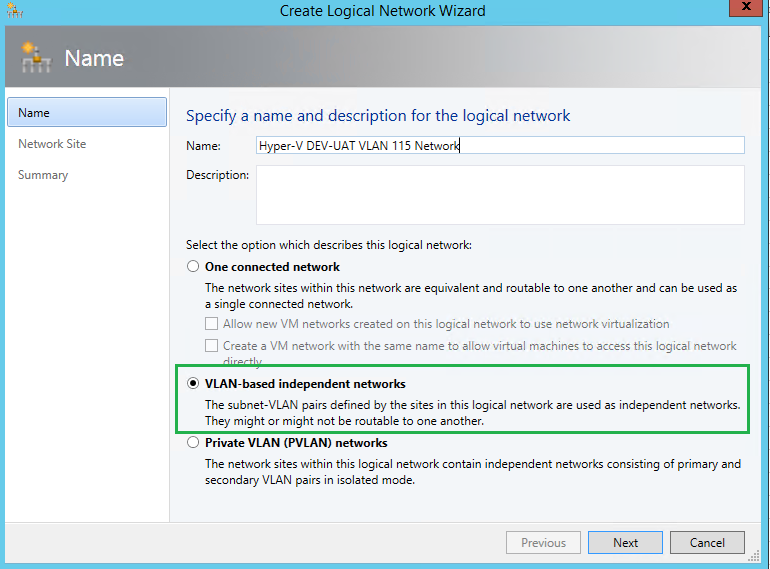
Here you need to specify the IP subnet and VLAN ID, and apply it to your Host(s) group.
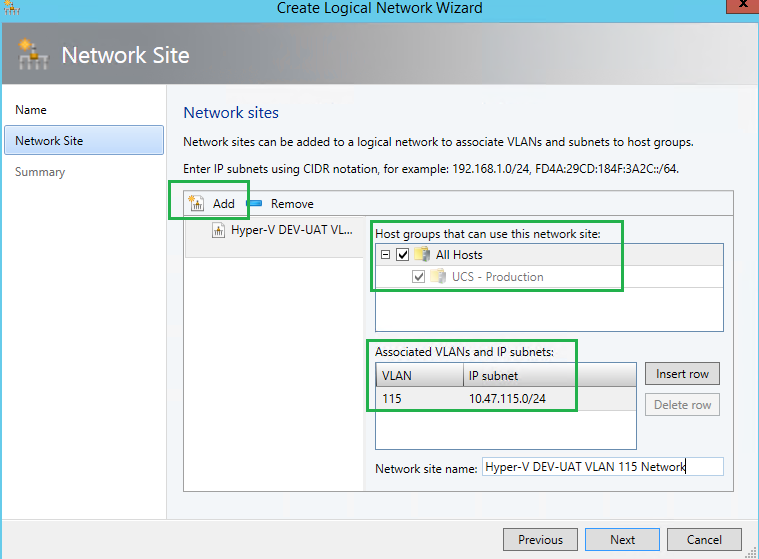
Step 4, SCVMM – Create IP Pool(s)
Once you create all of your logical networks, you can now create IP Pools. IP Pools will allow you to manage your logical network, and ensure there are no duplicate IPs consumed. You can also reserve IPs for VIPs, etc. In the screenshot below, as you can see, within my “Production” VM network traffic, my IP range states at 10.47.101.100/24 and ends at 10.47.101.252. This allows 155 IPs to be used. If the IP Pool is soon to be exhausted, this setting configuration can be changed to increase the scope. But for now, I know 155 IPs is more than enough.
By right-clicking on the Logical Network you just created, select “Create IP Pool“.
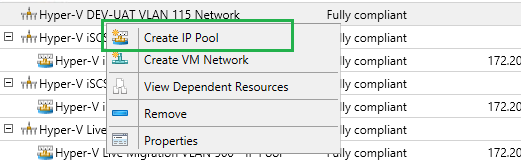
You will need to bound the IP Pool to the Logical Network.
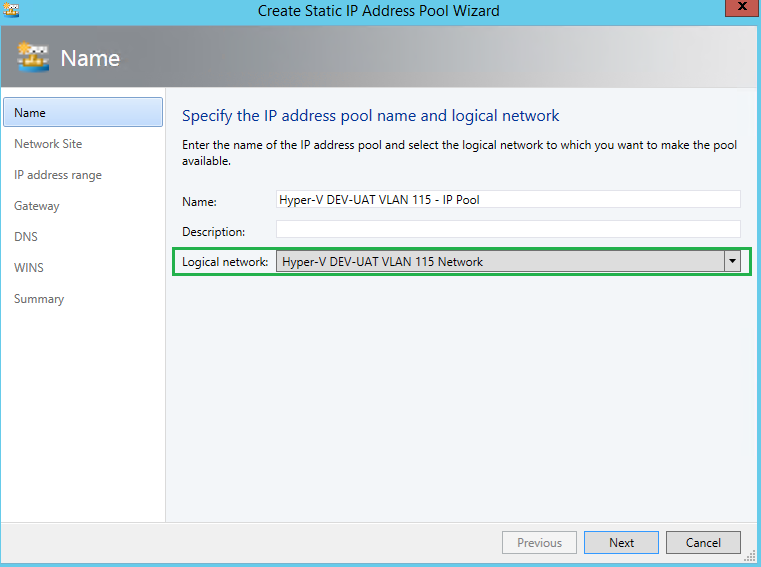
Choose, “Use an existing network site” and ensure the right network site and IP subnet populated.

Here, I am defining a range of IPs for my Pool. Although I know 155 IPs are more than enough, and will never need all 254 IPs, I am comfortable with the range starting at 100.
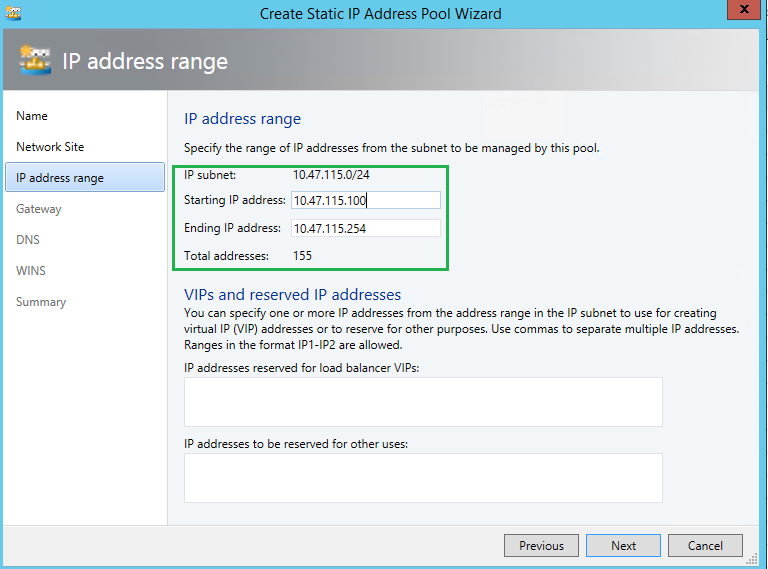
As you can see here, I have also specified the Gateway and provided 2 DNS servers for the IP Pool. When a new VM will be created, all of the IP Properties will be pulled from here and populated once the VM has been built.
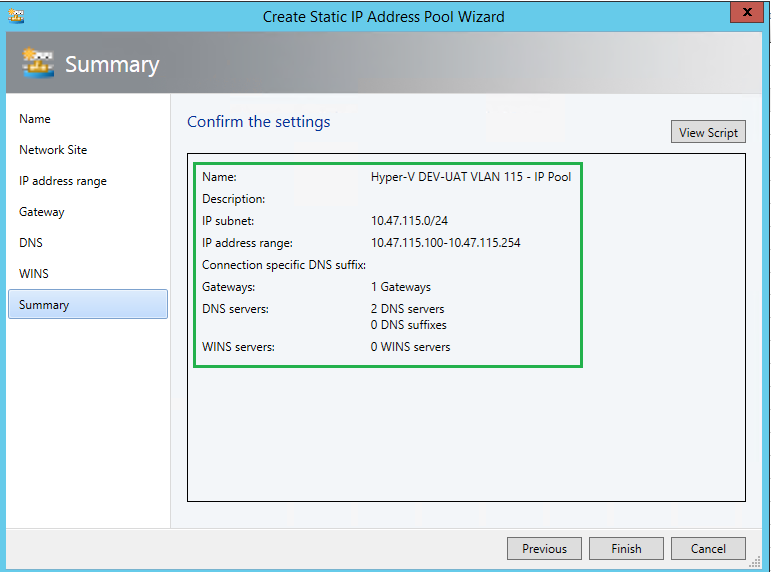
At the end of all this, your Logical Network Fabric could look something like this, with your Logical Networks and IP Pools per network.

Step 5, SCVMM – Create VM Networks + IP Pools
Within the VMs and Services pane, we will now need to create VM networks. This will be assoicated to our Logical Networks we just created. Within the creation process, we will need to specify the Logical network bound to this VM network. Here I created IP Pools again. I find this process of IP Pools a bit odd/redundant. I have IP Pools in both the Logical Network and the VM Network.
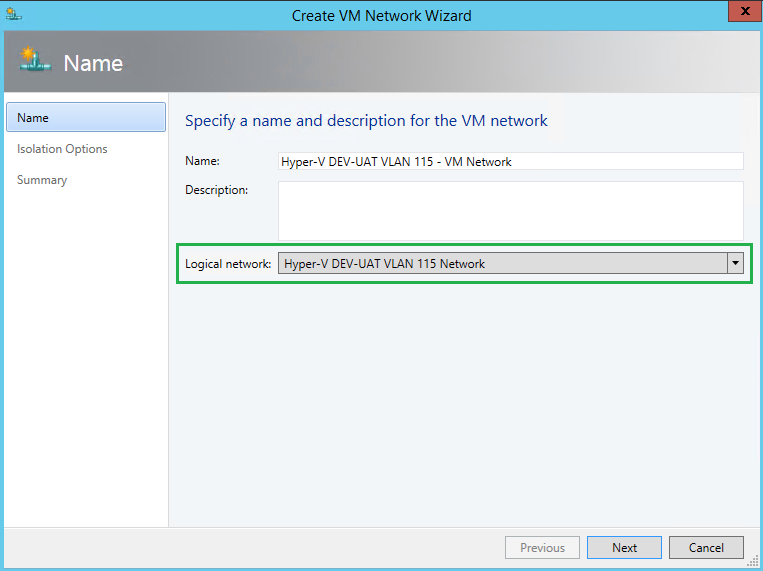
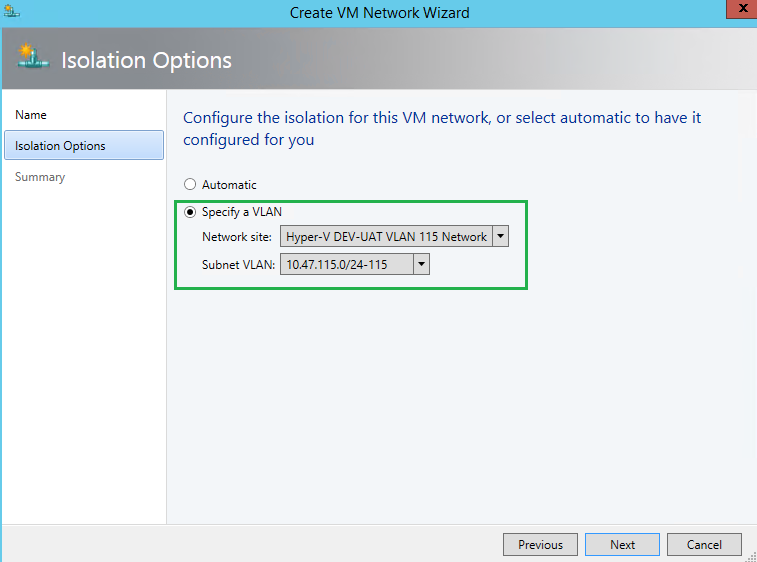
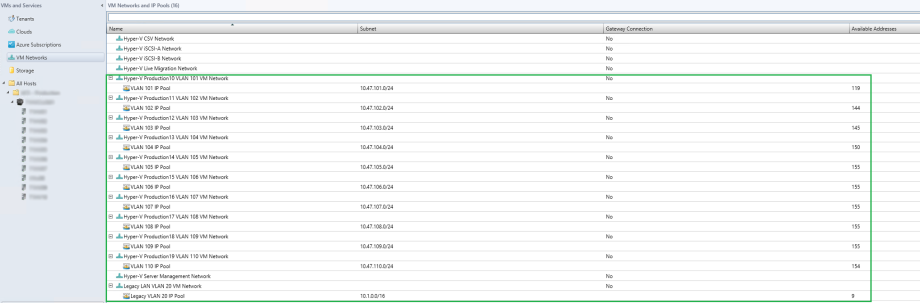
Step 6, SCVMM – Creating Uplink Port Profile
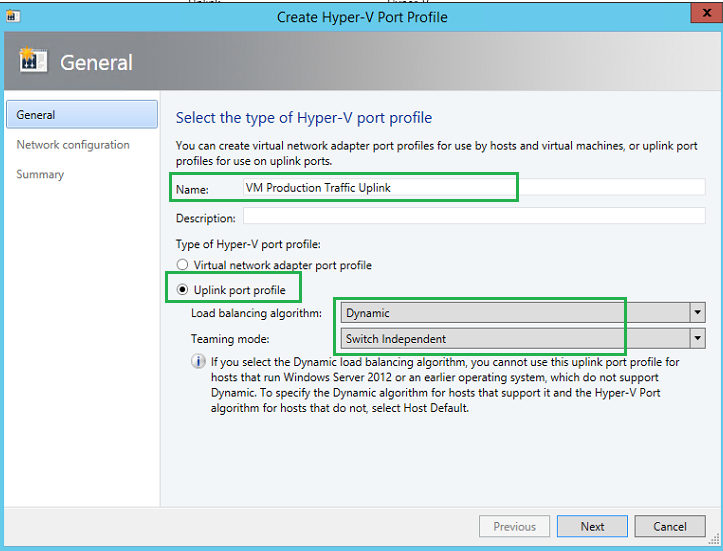
Now we need to create the Uplink Port Profile for our VM Production Traffic. Unfortunately with SCVMM 2012 R2 UR8, SCVMM does not come with a default Uplink port profile, so we must create one. Microsoft best practice indicates using a Dynamic and Switch Independent for the Hyper-V workload.
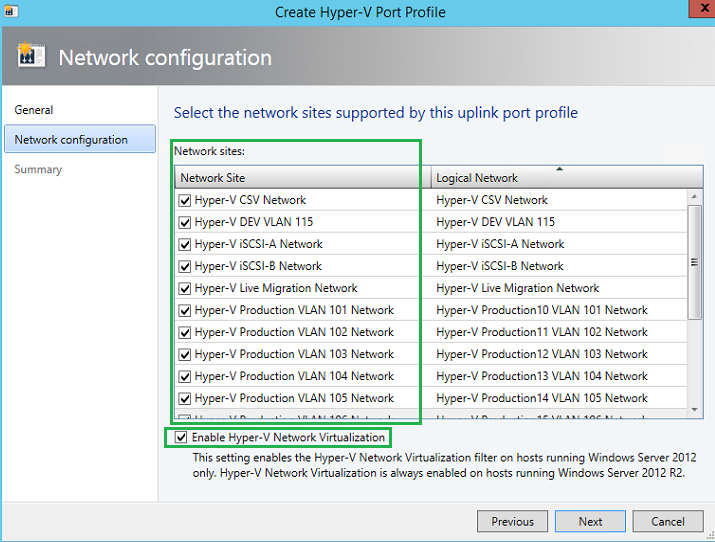
Now we will need to bound all the networks we previous created to the Uplink Port Profile. Here VMM will tell the hypervisors how they are connected and mapped to the network fabric. iSCSI traffic, Live Migration, VM Production, CSV-Heartbeat, etc.
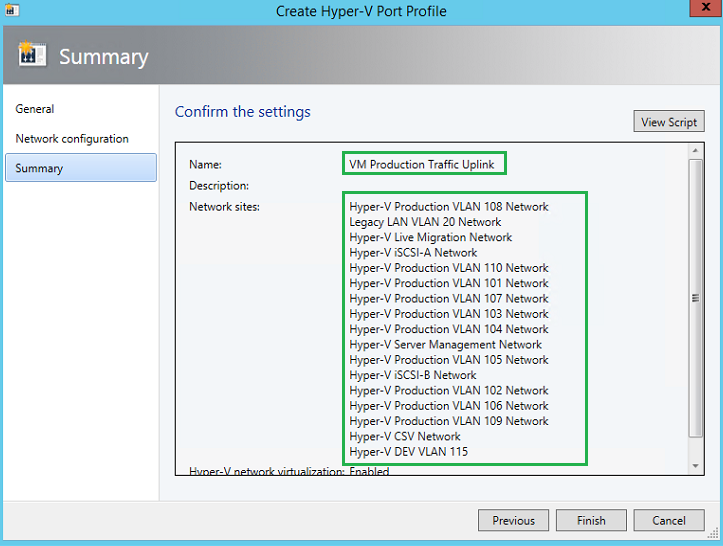
Step 7, SCVMM – Create Logical Switch
Now we will create the logical switch, or also known as a vSwitch. The logical switch is the last part of the fabric puzzle. This logical switch will contain the Uplink Port Profile along with the Virtual port profiles (if we chose to manage QoS via SCVMM).
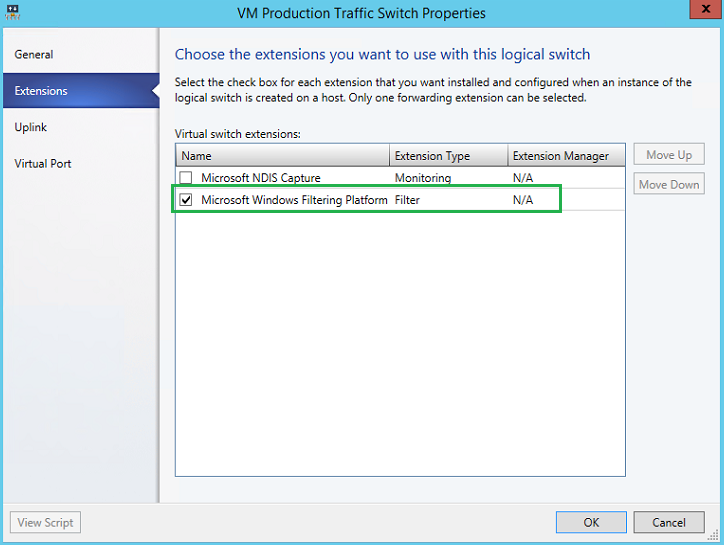
Within the Logical Switches – Fabric, we will create a new Logical switch. In my scenario, I have not made use of SR-IOV (Single Root – Input Output Virtualization).

We will use the default Microsoft Windows Filtering Platform for our vSwitch extension.
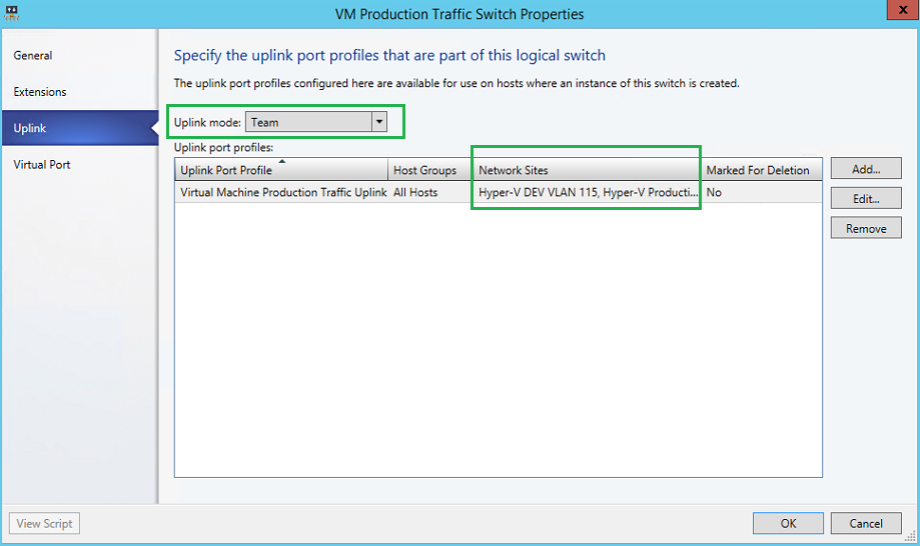
Here will will specify the uplink port profile(s) that will be associated to the logical switch. We will Team the mode, and add our Production Uplink/Network sites.
We will need to specify the port classifications for each virtual port for the logical switch. Here you can see we are using three classes, high, medium and low bandwidth.

Step 8, SCVMM – Assign Logical Switch to Hypervisor
Finally, we now need to assign the logical switch to our hypervisor(s). Navigate to (each) the host group within the fabric work-space and within each hypervisors properties, navigate to the Virtual Switches. Select “New Virtual Switch“. Here we will specify which (in our case only 1) Uplink port profile to use on the physical adapter. Since my two vNICs will be teamed, I will have two (2) adapters bound to the same Uplink port profile.

Now you are ready to start building machines, making use of your network fabric, and maximizing System Center Virtual Machine Manager 2012R2’s power.
If you have any questions, please drop me a line, and/or need some guidance.
'IT이야기 > Hyper-V' 카테고리의 다른 글
| Adding ESX/vCenter to SCVMM (0) | 2022.11.29 |
|---|---|
| Creating a Converged Network Fabric with SCVMM 2012R2 (0) | 2022.11.29 |
| Deploying and Configuring Storage Spaces Direct (S2D) (1) | 2022.11.29 |
| Adding servers or drives to Storage Spaces Direct (0) | 2022.11.29 |
| Adding servers or drives to Storage Spaces Direct (0) | 2022.11.29 |

















{kind=link}