This blog post will focus on deploying Storage Spaces Direct (S2D) with Windows Server 2016 (steps with Server 2019 should be very-very similar, if not exact…) in a RoBo (Remote Office Branch Office) configuration with Dell Ready Nodes (S2DRN) leveraging RDMA (Remote Direct Memory Access). Now that is a mouthful, so let’s focus on what is Storage Spaces Direct first.
What is Storage Spaces Direct? With Server 2016, Microsoft introduced Storage Spaces Direct (S2D) with the release of Server 2016. S2D allows you to take industry-standard servers and leverage the internal local drives within the nodes and create a highly-available, highly-scalable software defined storage. Using hyper-converged or converged architecture, you are able to quickly deploy, scale storage, while implementing features such as storage tiers, caching, all while taking advantage of RDMA networking.
What is RDMA? Remote Direct Memory Access, or in short, RDMA, is an enterprise networking technology that allows you to exchange data through memory, without consuming the CPU or Operating System kernel. RDMA allows your applications to have high IOPS and with very low latency, while leveraging either RoCe (RDMA over Converged Ethernet) or iWARP (Internet Wide Area RDMA Protocol).
Note: the steps below focus on a single node of a 2-node cluster. All the steps below need to be executed on the secondary node.
Network Connectivity
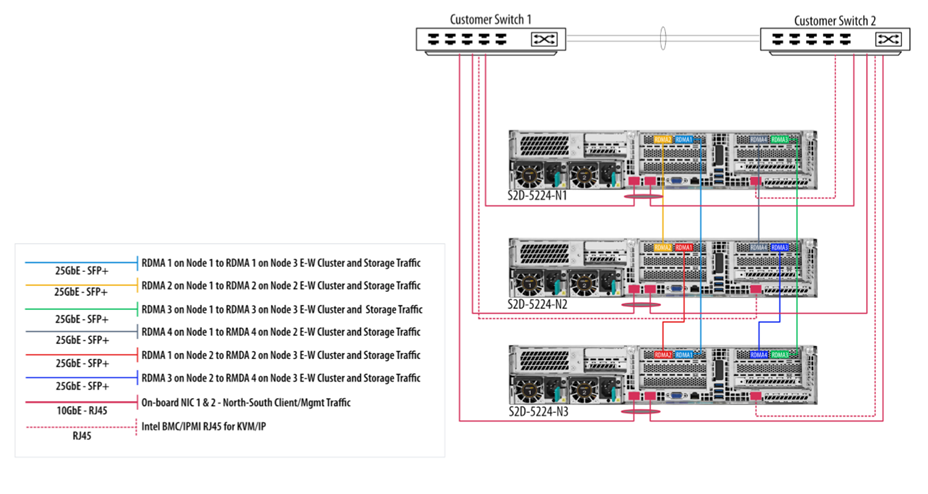
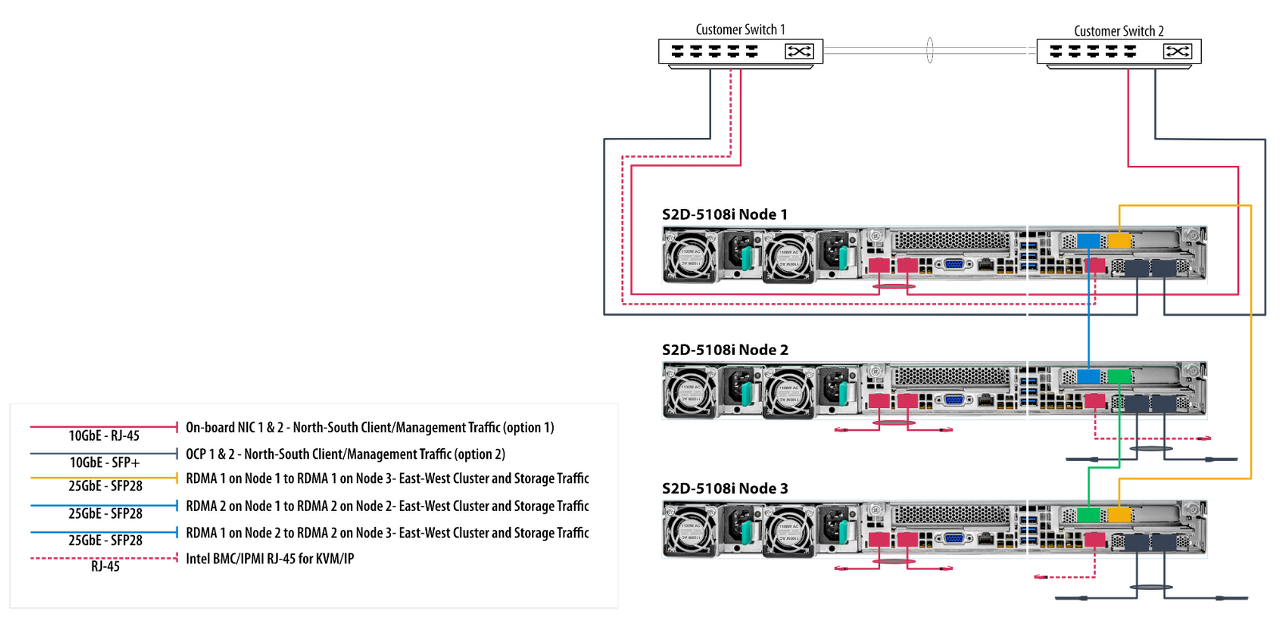
Before we begin implementing, deploying and configuring we need to plan out the networking connectivity design. However before we do that, we need to understand what our design will look like. Below is a high-level diagram that illustrates the network connectivity for the host management and VM traffic, and the RDMA (Storage) traffic.
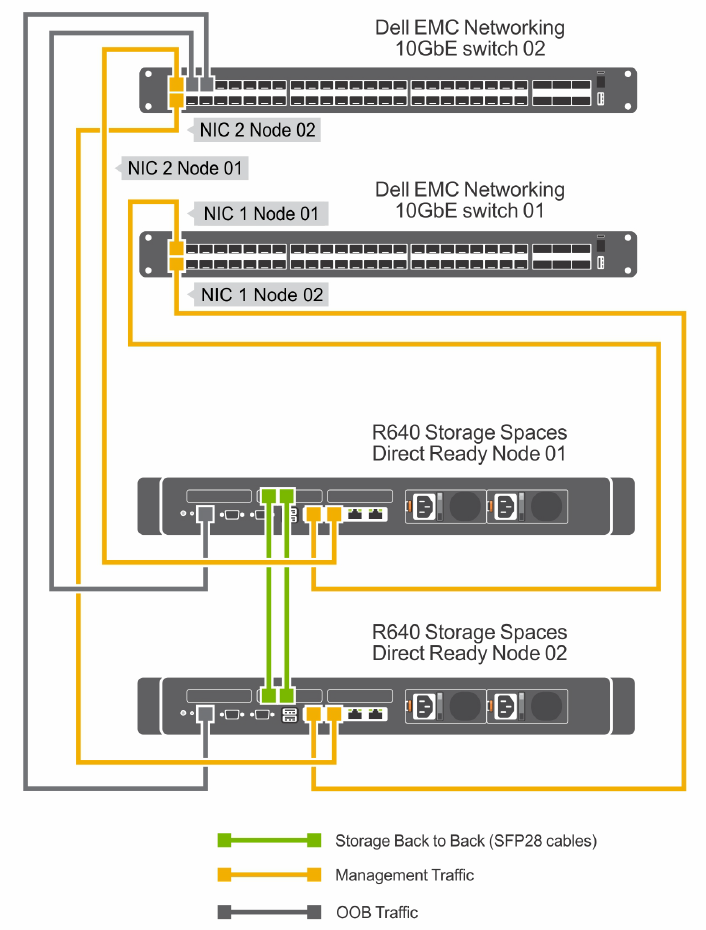
Network Configuration
Next we should map out our IP configuration. With this 2-node deployment we know we need the following network adapters and the following IPs.
| Traffic Class | Purpose | Minimum IPs required | VLAN ID | Tagged/Untagged | IP Address Space | VLAN IP Address |
| Out of Band (iDRAC) | Remote Management | 2 | Untagged | /29 | ||
| Management (Host) | Management of Cluster and Cluster Nodes | 3 | Tagged/Untagged | /29 | ||
| Storage 01 | SMB Traffic | 2 | Tagged/Untagged | /29 | ||
| Storage 02 | SMB Traffic | 2 | Tagged/Untagged | /29 |
Now that we have defined our networking configuration, we can move forward with booting the nodes, and making some necessary changes to the BIOS.
BIOS Configuration
Launch the node, and log into the BIOS (usually F2 at the Dell prompt)… Next go to the Device settings and let’s configure the RDMA/QLogic adapters.
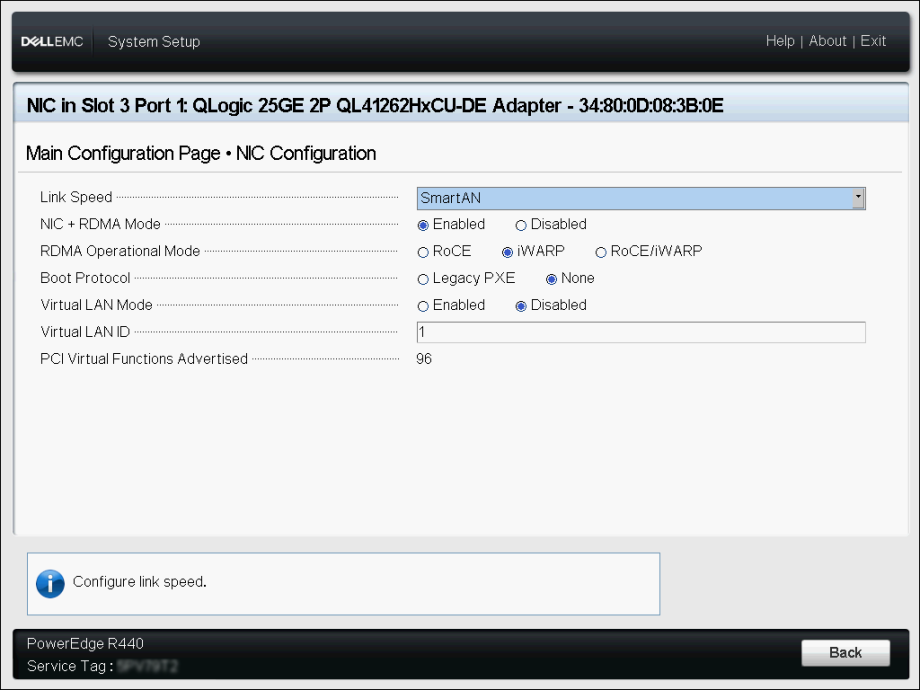
Your configuration should look similar to this. In my instance, I am leveraging iWARP and not RoCE. By default, the adapters will allow for both modes, but we want to force iWARP only.
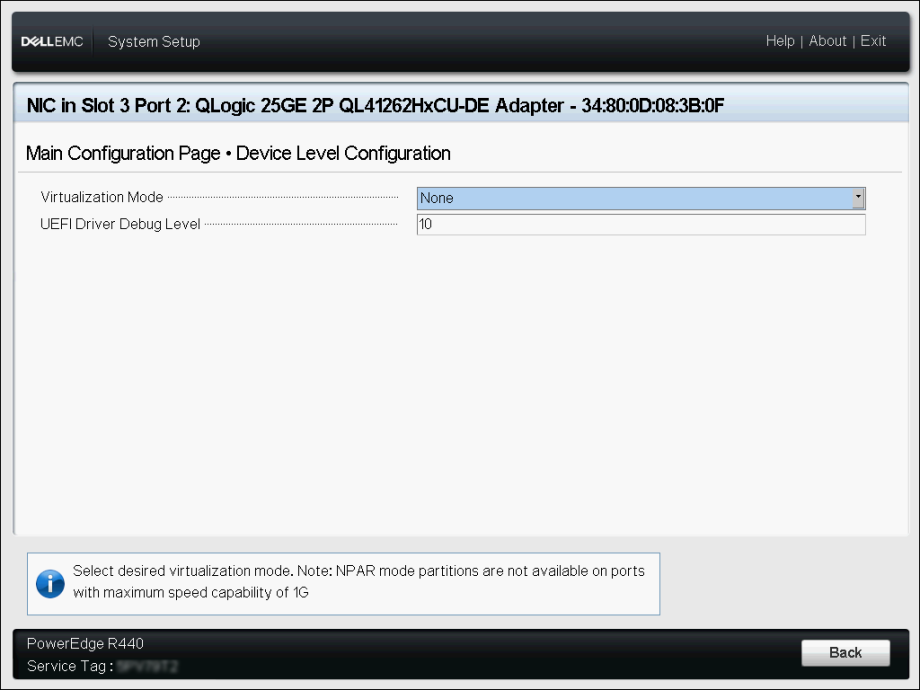
Disable Virtualization Mode
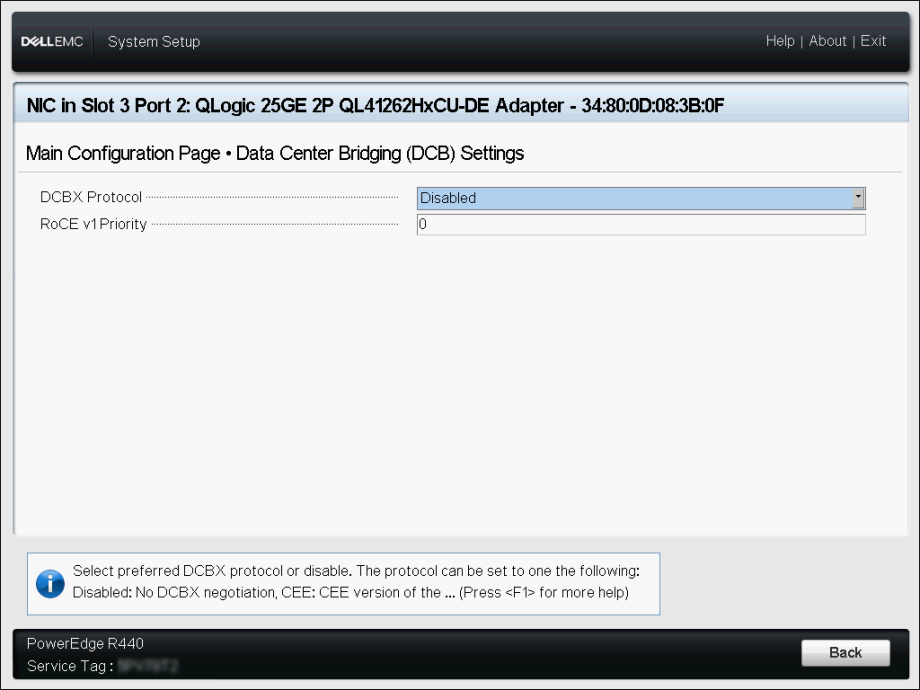
Disable DCBX (Data Center Bridging)
- Link Speed: SmartAN
- NIC + RDMA Mode: Enabled
- RDMA Operation Mode: iWARP
- Virtual LAN ID: 1 (which is default)
Remember, this needs to be done to both RDMA adapters!!! Once the settings have been applied, and saved, go ahead and reboot the node. Remember to do the second node too!
Install & Update Operating System
Next, we now need to install the Operating System. As best practice, once the OS is installed, update the OS and update all network drivers.
Validate & Rename Network Adapters
Also, it is a good idea to rename the Network adapters. Before we do that, let’s just confirm the adapters are there and look right.
|
1
|
Get-NetAdapter
|

Install Windows Features & Roles
Once the OS has been installed, and patched. Next we now need to install the necessary roles and features, ie. Hyper-V, Failover Manager, etc.
|
1
|
Install-WindowsFeature -Name Hyper-V, Failover-Clustering -IncludeAllSubFeature -IncludeManagementTools -Verbose -Restart
|
Configure Host Network
Now we need to configure the host management network. In this step we will create a SET switch (Switch Embedded Teaming). This switch will not only team the two network (host) adapters but at the same time a SET switch will be created that will be leveraged by the guest VMs via Hyper-V.
|
1
|
New-VMSwitch -Name S2DSwitch -AllowManagementOS 0 -NetAdapterName 'NIC1','NIC2' -MinimumBandwidthMode Weight -Verbose
|
Within this code, note, NIC1 and NIC2 are the host management adapters that were renamed to make life easier.
Now we need to create and configure the host management adapter. We will do this by executing the following cmdlet. Please note, in my environment, the Host Management network is untagged.
|
1
|
Add-VMNetworkAdapter -ManagementOS -Name 'Management' -SwitchName S2DSwitch -Passthru | Set-VMNetworkAdapterVlan -Untagged –Verbose
|
Once we execute this command, and run the Get-NetAdapter cmdlet, we can now see we have an additional network adapter.

In the event you need to tag your Management adapters you can use the following cmdlet below as reference.
|
1
2
|
Set-NetAdapterAdvancedProperty -Name 'SLOT 3 PORT 1' -DisplayName 'VLAN ID' -DisplayValue 103 -Verbose
Set-NetAdapterAdvancedProperty -Name 'SLOT 3 PORT 2' -DisplayName 'VLAN ID' -DisplayValue 104 -Verbose
|
Great, now we can add the nodes to the domain, and set the Management network adapters with static IPs.
Create the Cluster, Configure Witness, Enable Storage Spaces Direct
Now that are nodes are domain joined, and static IPs have been applied to the host management network, we can now begin creating the cluster.
In the code below, I am going to create the cluster; add the two nodes to the cluster; provision the Quorum witness (file witness) and enable Storage Spaces Direct on the cluster.
|
1
2
3
4
5
6
|
$cluster="Cluster_Name"
New-Cluster -name $cluster -Node "node01", "node02" -StaticAddress "IP Address" -NoStorage -Verbose
#assign cluster quorum
Set-ClusterQuorum -Cluster $cluster -FileShareWitness "\\server\filewitness\UNCPatch"
#enable storage spaces direct
Enable-ClusterS2D -Verbose
|
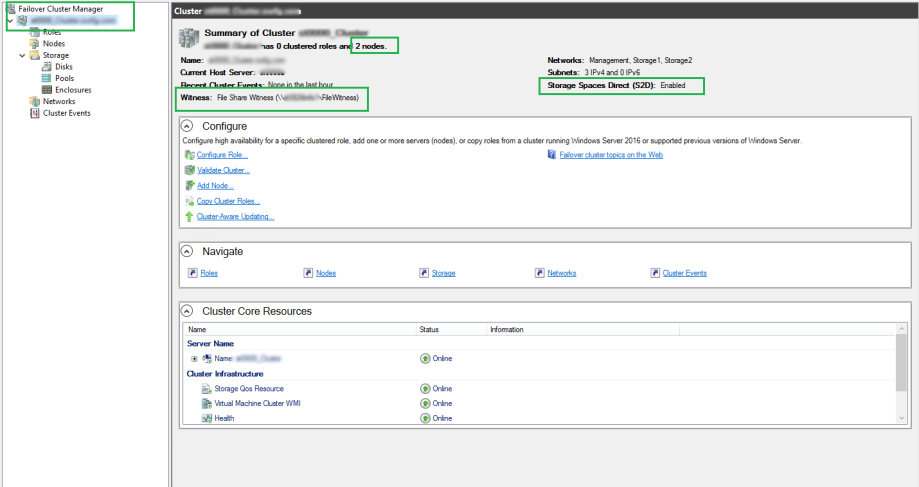
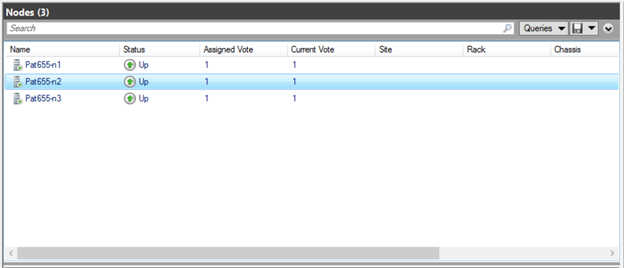
Once we have executed the commands above, if we launch Failover Manager, we can now see the created Cluster, with the 2 nodes, and Storage Spaces Direct enabled.

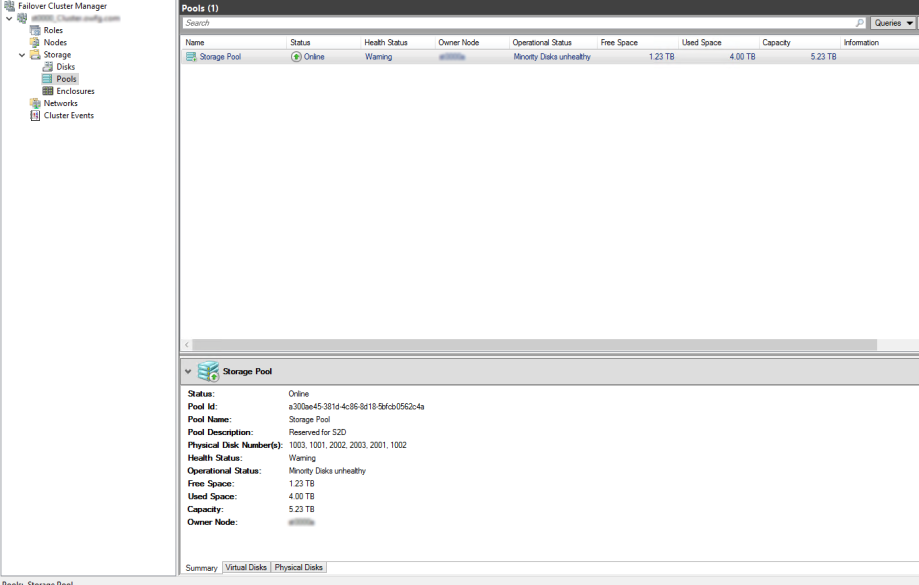
If we go into the Pool, we can also now see our Software Defined Storage Pool. We now can create volumes off of this pool.
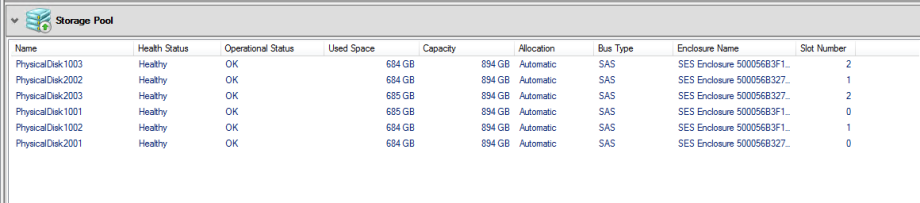
If we go into the Enclosures, we can now also see all the disks available within the nodes and all disks that are members of the Storage Pool.
Great, now we need to do some configuration on the RDMA Adapters… Also to note, in this scenario I have leveraged a file share witness for the cluster. I would highly recommend considering or using Azure Cloud Witness. The egress traffic is next to 0, and you can connect several clusters to the storage account. For more information, see the following blog post(s): HERE.
Change RDMA mode to iWARP on QLogic Adapters
Again, remember which RDMA adapter is which. As mentioned previously, I renamed all of the network adapters to keep things simple and easy to remember.
|
1
2
|
Set-NetAdapterAdvancedProperty -Name 'SLOT 3 PORT 1' -DisplayName 'RDMA Mode' -DisplayValue 'iWarp'
Set-NetAdapterAdvancedProperty -Name 'SLOT 3 PORT 2' -DisplayName 'RDMA Mode' -DisplayValue 'iWarp'
|
Now we can leverage the QLogic adapters with RDMA via iWARP for our Storage traffic.
Create Cluster Shared Volumes (CSV)
Now that our cluster is created, nodes have been added, RDMA is configured, we can now create a CSV that will be leveraged by the VMs as their data store. We will do this by creating the CSV with the following cmdlet.
|
1
|
New-Volume -StoragePoolFriendlyName "Storage Pool" -FriendlyName "Volume01" -FileSystem CSVFS_ReFS -size 2TB
|
Now I elected to keep the CSV small with a 2TB volume, however I did have another 3TB to work with.
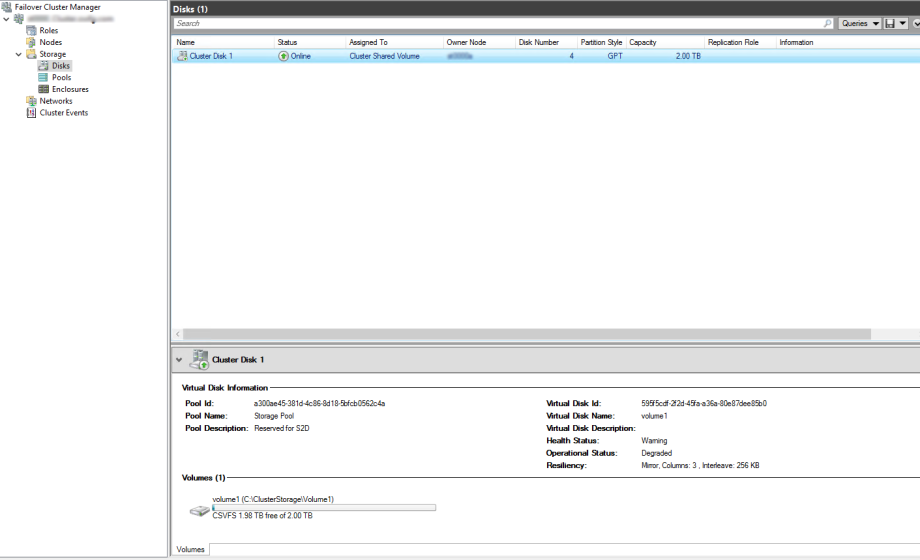
Update Live Migration
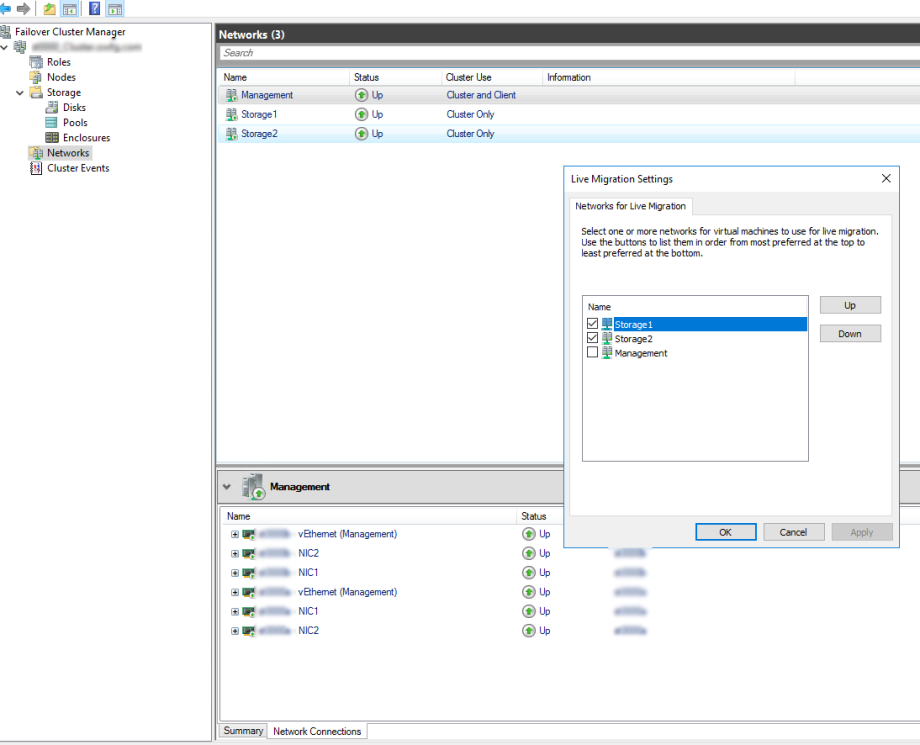
We are almost there, we now need to update the Live Migration network. This will ensure we make use of the RDMA network and not the Management network. We will do this via Failover Manager console.
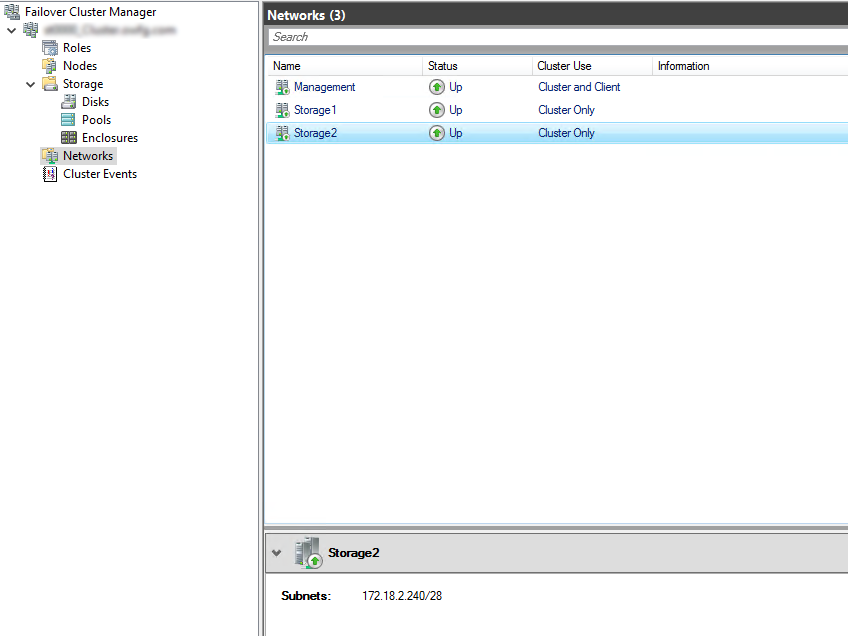
Also a good idea to rename the networks. As you can see, I have renamed my storage networks to Storage1 and Storage2, and the host management network to Management.
Go to the Failover Manager Console >> Right Click Networks >> Select Live Migration Settings >> deselect the Management network.
You may have also noticed, I have configured the networks and their cluster use. Storage networks will be only available for the cluster, and the Management network will be available for both the cluster and client (guest VMs).
Next steps
We have now successfully created a Storage Spaces Direct cluster, leveraging RDMA networking and using the iWARP protocol. We now also created a SET switch that can be leveraged by our VMs as their network adapter. We have now also created a Storage Pool, with a volume dedicated for our VM disks leveraging the Cluster Shared Volume.
Next steps is now to create a VM and leveraging Storage Spaces Direct!
'IT이야기 > Hyper-V' 카테고리의 다른 글
| Creating a Converged Network Fabric with SCVMM 2012R2 (0) | 2022.11.29 |
|---|---|
| Creating a Converged Network Fabric with SCVMM 2012R2 (0) | 2022.11.29 |
| Adding servers or drives to Storage Spaces Direct (0) | 2022.11.29 |
| Adding servers or drives to Storage Spaces Direct (0) | 2022.11.29 |
| Storage Spaces Direct hardware requirements (0) | 2022.11.29 |

















{kind=link}