조인이란?
두개이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법입니다. 자신이 검색하고 싶은 컬럼이 다른 테이블에 있을경우 주로 사용하며 여러개의 테이블을 마치 하나의 테이블인 것처럼 활용하는 방법입니다. 보통 Primary key혹은 Foreign key로 두 테이블을 연결합니다. 테이블을 연결하려면 적어도 하나의 칼럼은 서로 공유되고 있어야합니다.고등학교 수학시간때 배웠던 벤다이어그램을 활용하면 쉽게 이해할 수 있습니다.
INNER JOIN

쉽게말해 교집합이라고 생각하시면 됩니다. 기준테이블과 Join한 테이블의 중복된 값을 보여줍니다.
결과값은 A의 테이블과 B테이블이 모두 가지고있는 데이터만 검색됩니다.
--문법-- SELECT 테이블별칭.조회할칼럼, 테이블별칭.조회할칼럼 FROM 기준테이블 별칭 INNER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키.... --예제-- SELECT A.NAME, --A테이블의 NAME조회 B.AGE --B테이블의 AGE조회 FROM EX_TABLE A INNER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP AND A.DEPT = B.DEPT
LEFT OUTER JOIN
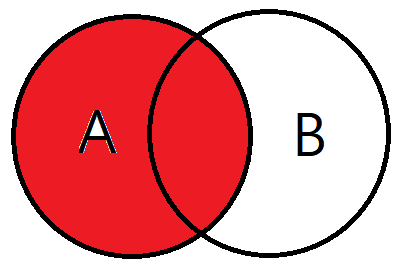
기준테이블의 값 + 테이블과 기준테이블의 중복된 값을 보여줍니다.
왼쪽 테이블을 기준으로 JOIN을 하겠다고 생각하시면 됩니다.
그럼 결과값은 A테이블의 모든 데이터와 A테이블과 B테이블의 중복되는 값이 검색되겠네요
--문법-- SELECT 테이블별칭.조회할칼럼, 테이블별칭.조회할칼럼 FROM 기준테이블 별칭 LEFT OUTER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키 ..... --예제-- SELECT A.NAME, --A테이블의 NAME조회 B.AGE --B테이블의 AGE조회 FROM EX_TABLE A LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP AND A.DEPT = B.DEPT
RIGHT OUTER JOIN

LEFT OUTER JOIN의 반대입니다.
오른쪽 테이블을 기준으로 JOIN을 하겠다고 생각하시면 됩니다.
그럼 결과값은 B테이블의 모든 데이터와 A테이블과 B테이블의 중복되는 값이 검색되겠군요
--문법-- SELECT 테이블별칭.조회할칼럼, 테이블별칭.조회할칼럼 FROM 기준테이블 별칭 RIGHT OUTER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키 ..... --예제-- SELECT A.NAME, --A테이블의 NAME조회 B.AGE --B테이블의 AGE조회 FROM EX_TABLE A RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP AND A.DEPT = B.DEPT
FULL OUTER JOIN
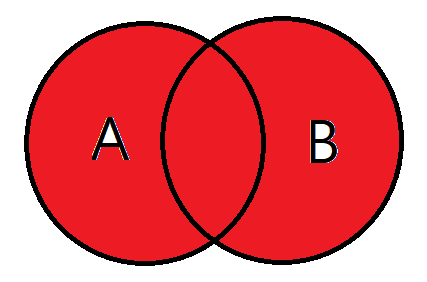
쉽게말해 합집합을 생각하시면 됩니다.
A테이블이 가지고 있는 데이터 , B테이블이 가지고있는 데이터 모두 검색됩니다.
사실상 기준테이블의 의미가 없습니다.
--문법-- SELECT 테이블별칭.조회할칼럼, 테이블별칭.조회할칼럼 FROM 기준테이블 별칭 FULL OUTER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키 ..... --예제-- SELECT A.NAME, --A테이블의 NAME조회 B.AGE --B테이블의 AGE조회 FROM EX_TABLE A FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP AND A.DEPT = B.DEPT
CROSS JOIN

크로스 조인은 모든 경우의 수를 전부 표현해주는 방식입니다.
기준테이블이 A일경우 A의 데이터 한 ROW를 B테이블 전체와 JOIN하는 방식입니다.
그러니 결과값도 N * M 이 되겠죠?
위사진에서는 A테이블에 데이터가 3개, B테이블에는 데이터가 4개가 있으므로 총 12개가 검색됩니다.
--문법(첫번째방식)-- SELECT 테이블별칭.조회할칼럼, 테이블별칭.조회할칼럼 FROM 기준테이블 별칭 CROSS JOIN 조인테이블 별칭 --예제(첫번째방식)-- SELECT A.NAME, --A테이블의 NAME조회 B.AGE --B테이블의 AGE조회 FROM EX_TABLE A CROSS JOIN JOIN_TABLE B ===================================================================================== --문법(두번째방식)-- SELECT 테이블별칭.조회할칼럼, 테이블별칭.조회할칼럼 FROM 기준테이블 별칭,조인테이블 별칭 --예제(두번째방식)-- SELECT A.NAME, --A테이블의 NAME조회 B.AGE --B테이블의 AGE조회 FROM EX_TABLE A,JOIN_TABLE B
SELF JOIN

셀프 조인은 자기자신과 자기자신을 조인한다는 의미입니다.
하나의 테이블을 여러번 복사해서 조인한다고 생각하시면 될듯합니다.
자신이 가지고 있는 칼럼을 다양하게 변형시켜 활용할 경우에 자주사용합니다.
--문법-- SELECT 테이블별칭.조회할칼럼, 테이블별칭.조회할칼럼 FROM 테이블 별칭,테이블 별칭2 --예제-- SELECT A.NAME, --A테이블의 NAME조회 B.AGE --B테이블의 AGE조회 FROM EX_TABLE A,EX_TABLE B
'IT이야기 > MS-SQL' 카테고리의 다른 글
| DB Lock 및 Kill 방법 (0) | 2021.08.12 |
|---|---|
| [MSSQL] 실습 SELECT, FROM, WHERE, BETWEEN, AND, IN, LIKE, ANY, ALL 등 (0) | 2020.02.06 |
| 조건문 (CASE WHEN, IF) 함수 사용법 & 예제 (0) | 2019.10.29 |
| SET NOCOUNT 사용법 (0) | 2019.10.29 |
| 피벗테이블 (0) | 2019.10.29 |