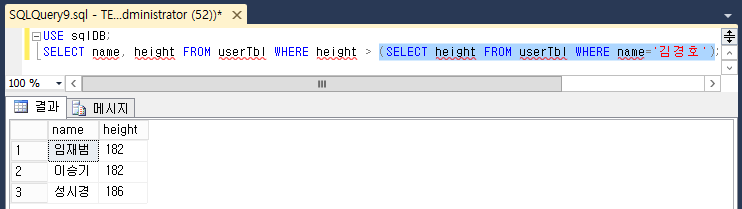
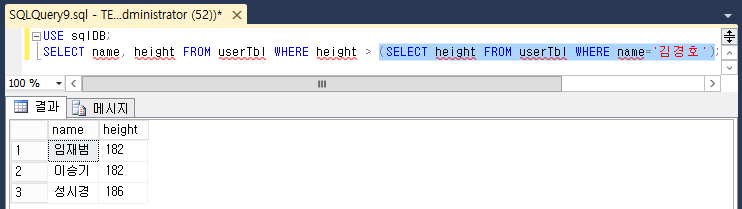
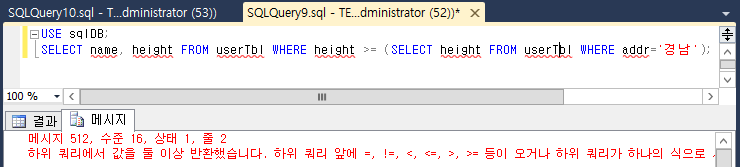
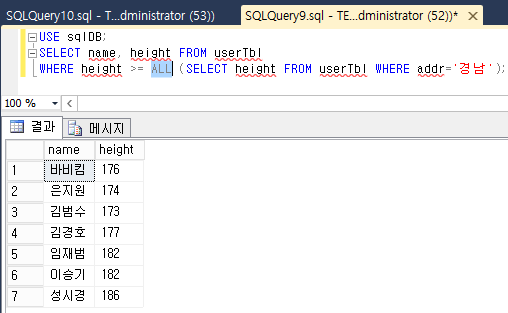
날짜 함수
select getdate() <= 현재 시스템의 날짜를 가저온다. (시스템에 설정된 나라의 형식을 따른다.)
select Year(getdate()),month(getdate()),day(getdate()) <= 년,월,일 을 뽑는다
select getdate(),datename(Weekday,getdate()) <= 요일을 뽑는다
select datediff(yy,'1945-08-15',getdate()) <= 적어준 날의 년과 현재날의 년과의 차이를 출력
select datediff(dd,'1945-08-15',getdate()) <= 적어준 날의 일과 현재날의 일과의 차이를 출력
-- convert(바꿀형식, 원본데이타) ; 바꿀형식으로 데이타를 바꾼다 아래의 예는 문자형으로 바꾸어 문자와 '+' 기호를 사용하여 결합하는 예이다
select convert(char(4),year(getdate())) + '년'
--select * from insa => ex) example problem
select name, datediff(yy,ibsa_date,getdate()) as 근무년,datediff(dd,ibsa_date,getdate()) as 근무일
from insa
where datediff(dd,ibsa_date,getdate()) > 0
select name as 이름, convert(char(4), year(ibsa_date)) + '년' + convert(char(2),month(ibsa_date)) + '월' +
convert(char(2), day(ibsa_date)) + '일' + datename(weekday,ibsa_date) as 입사일 from insa
수식관련 내장함수
floor => 소수점아래 제거,
round => 반올림함수, n 자리까지 남김. 0 인경우 일의자리까지 남김
select floor(13.7), floor(-13.7), round(13.75, 1)
result -> 13 -14 13.80
select floor(13.7), floor(-13.7), round(13.75, 0)
result -> 13 -14 14.00
select floor(13.7), floor(-13.7), round(13.75, -1)
result -> 13 -14 10.00
--select replicate('*',10) -- 해당문자를 n 번 반복 예에서는 * 을 10번 출력
select name, (gi_pay + su_pay) as [급여], replicate('*', floor((gi_pay + su_pay)/100000)) as [그래프]
from insa
stuff 내장함수
select stuff('영업팀', 3, 1, '부') as stuff
select stuff('서울시', 3, 1, '특별시') as stuff
select name as [이름], stuff(buseo, 3, 1, '팀') as [팀명] from insa
select name, gi_pay, su_pay from insa order by gi_pay desc, su_pay
select * from insa order by ibsa_date desc, substring(ssn,1,6)
select * from insa order by convert(varchar(10),ibsa_date, 102) desc, substring(ssn,1,6)
select top 5 name, city, (gi_pay + su_pay) as [보수], ssn as [주민등록번호] from insa
where city='서울' order by (gi_pay + su_pay ) desc
select top 5 with ties name, city, (gi_pay + su_pay) as [보수], ssn as [주민등록번호] from insa where city='서울' order by (gi_pay + su_pay ) desc
select top 25 percent name, city, (gi_pay + su_pay) as [보수], ssn as [주민등록번호] from insa where city='서울' order by (gi_pay + su_pay ) desc
select top 25 name, city, (gi_pay + su_pay) as [보수], ssn as [주민등록번호] from insa
where city='서울' order by (gi_pay + su_pay ) desc
SELECT * FROM INSA WHERE GI_PAY >= 1000000 AND GI_PAY <= 2000000
SELECT * FROM INSA WHERE GI_PAY BETWEEN 1000000 AND 2000000
--SELECT NAME AS 이름, IBSA_DATE AS 입사일 FROM INSA WHERE IBSA_DATE LIKE '%2004%'
SELECT NAME AS 이름, IBSA_DATE AS 입사일 FROM INSA
WHERE IBSA_DATE BETWEEN '2004-01-01' AND '2004-12-31'
문자함수
LEFT, RIGHT
LEFT는 지정해준 자릿수만큼 왼쪽에서부터 문자열을 반환한다.
당연히 RIGHT는 반대이다.
형식 : LEFT(문자, 자릿수)
LTRIM, RTRIM
LTRIM은 문자열의 왼쪽 공백을 제거한다. 역시 RTRIM은 반대일 경우 사용된다.
형식: LTRIM(문자)
LEN
LEN함수는 문자열에서 문자의 갯수를 추출한다.
형식: LEN(문자)
Len함수는 문자 뒤쪽의 공백은 문자로 계산하지 않는다.
UPPER, LOWER
UPPER는 소문자를 대문자로, LOWER는 대문자를 소문자로 바꾼다.
형식: UPPER(문자)
REVERSE
REVERSE는 문자열을 반대로 표시한다.
형식: REVERSE(문자열)
REPLACE
REPLACE함수는 지정한 문자열을 다른 문자열로 바꾸어준다.
형식: R-PLACE(문자, 타겟문자, 바꿀문자)
REPLICATE
REPLICATE함수는 문자열을 지정된 횟수만큼 반복한다.
형식: REPLICATE(문자, 횟수)
STUFF
STUFF함수는 문자열에서 특정 시작위치에서 지정된 길이만큼 문자를 바꾸어준다.
형식: STUFF(문자, 시작위치, 길이, 바꿀문자)
SUBSTRING
SUBSTRING은 STUFF와 비슷하지만 문자를 바꾸는 것이 아니라 그 문자를 반환한다.
형식: SUBSTRING(문자, 시작위치, 길이)
PATINDEX, CHARINDEX
PATINDEX와 CHARINDEX는 문자열에서 지정한 패턴이 시작되는 위치를 뽑아준다.
형식: PATINDEX(문자패턴, 문자) - 문자패턴은 Like 사용과 같다.
형식: CHARINDEX(문자패턴, 문자) - 문자패턴은 일반형식을 사용한다.
SPACE
SPACE함수는 지정한 수 만큼 공백을 추가한다.
형식: SPACE(횟수)
시간 및 날짜 함수
GETDATE()
GETDATE()는 현재 시간을 표시해준다.
DATEADD
DATEADD함수는 날자에 지정한 만큼을 더한다.
형식: DATEADD(날자형식, 더할 값, 날자)
DATEDIFF
DATEDIFF함수는 두 날자사이의 날자형식에 지정된 부분을 돌려준다.
형식: DATEDIFF(날자형식, 시작 날자, 끝 날자)
DATENAME
DATENAME함수는 지정한 날자의 날자형식의 이름을 돌려준다.
형식: DATENAME(날자형식, 날자)
DATEPART
DATEPART함수는 날자에서 지정한 날자형식부분만 추출해줍니다.
형식: DATEPART(날자형식, 날자)
주일은 일요일부터 1로 시작해서 토요일날 7로 끝나게 된다.
NULL 함수
ISNULL
ISNULL은 NULL값을 대체값으로 바꾼다.
형식: ISNULL(NULL값, 대체값)
NULLIF
NULLIF함수는 두개의 표현식을 비교하여 같으면 NULL을 반환한다.
형식: NULLIF(표현식1, 표현식2)
COALESCE
COALESCE함수는 NULL이 아닌 첫번째 표현식이 반환된다.
형식: COALESCE(표현식)
GETANSINULL
GETANSINULL은 데이터베이스의 기본 NULL 상태를 표시해준다.
형식: GETANSINULL(데이터베이스 이름)
테이블의 칼럼정보 보기
exec sp_columns sales
/* Substring 처리 */
select payterms from sales
select substring(payterms,1,3) from sales
/* 문자열연결 연산자 '+' */
select substring(payterms,1,4)+ ' 테스트' from sales
/*현재날짜 */
select getdate()
/* 1년후날짜 */
select getdate() + 365
/* 날짜데이타 변경 CONVERT(변경될문자열의 데이타타입및길이, 날짜데이타, 출력형식) */
select convert(varchar(30), getdate(), 2)
select convert(varchar(30), getdate(), 102)
/* YYYYMMDD 형식으로 가져오기( Varchar(8)로 설정 ) */
select convert(varchar(8), getdate(), 112)
/* 해당 [월] 만 가져오기 */
select datepart(mm,getdate())
select month(getdate())
/* 현재일자에 20개월추가 (월 추가) */
select dateadd(mm,20,getdate())
/* 현재일자에 100일 후의 날짜 */
select dateadd(dd,100,getdate())
/* Oracle 에서의 NVL함수에 대응하는 MS-SQL함수 */
NVL(price,0) ===> ISNULL(price,0)
/* 판매수량이 30권 이상인책에 대하여 각 서적별 판매수량총계 조회 */
select title_id as '서적코드' , sum(qty) as '판매수량' from sales
group by title_id
having sum(qty) >= 30
/* COMPUTE & COMPUTE BY 사용법 */
select type, title_id, price from titles
order by type
compute avg(price) by type
해당 select칼럼이 별로 Average값을 구해준다. ( Order by 반드시 필요 )
select type, title_id, price from titles
order by type
compute avg(price) by type
마지막행에 Select된 전체칼럼중 Average(price)칼럼에 대해 평균값을 구해준다.
/* Rollup & Cube */
select type, avg(price) from titles group by type --각 타입별 평균
select avg(price) from titles -- 전체평균